Data Services: Aggregating database requests for improved performance
Using data services to perform request aggregation to reduce database query latency

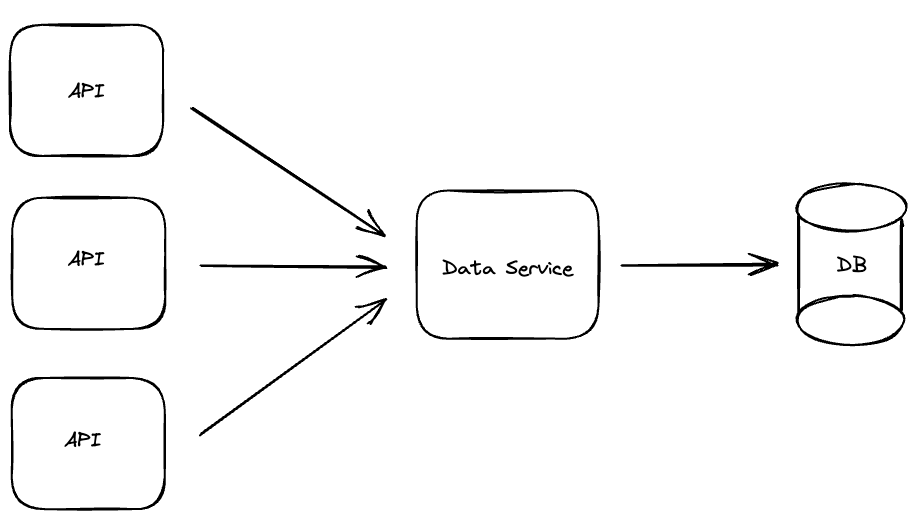
I've been investigating how to design a low latency chat service for large audiences, and in my research I came across this great article by Discord which describes how they handle trillions of chat messages in their architecture. One of the key improvements they cited was the concept of a Data Service.
As they describe, a data service is a service that acts as an intermediate layer between APIs requesting data and the database. The service can then shield the database from excessive load by aggregating identical requests, thereby improving database load and API response simultaneously.
This article is my exploration on how a data service could work, an analysis of when and why a data service could be beneficial and an implementation of one in NestJS. One key aspect that I felt was missing in the article was how an aggregated request failure would be handled, and in this article I will try to explore those failure scenarios.
What is a data service?
A data service is a service that acts as an intermediate layer between your API's requesting data and the database they are requesting data from.
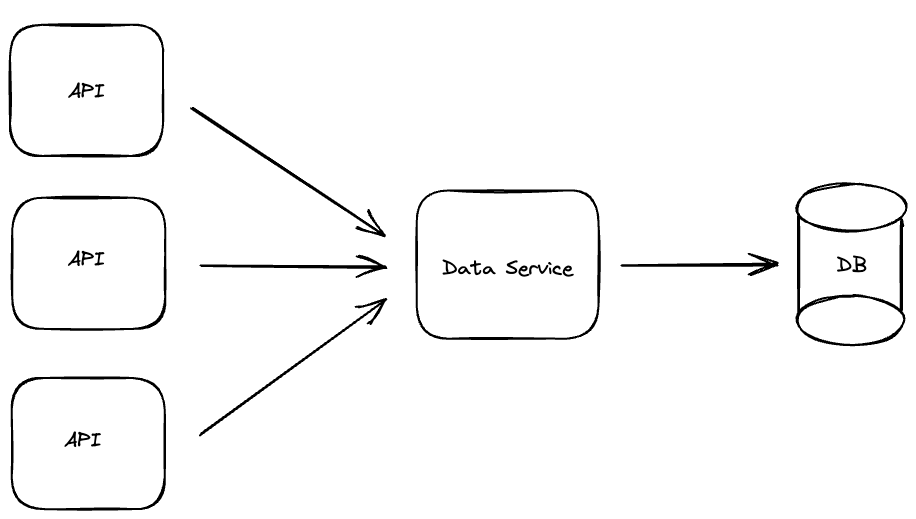
In this architecture, the data service is able to perform request aggregation which improves database performance. When the data service receives a request (ie. a database query) it first checks if an identical query is already running, if not it performs the request against the database. If however, there is already an identical query running, then this request simply subscribes to the result of the first request. By doing this concurrent identical requests can be aggregated into a single request.
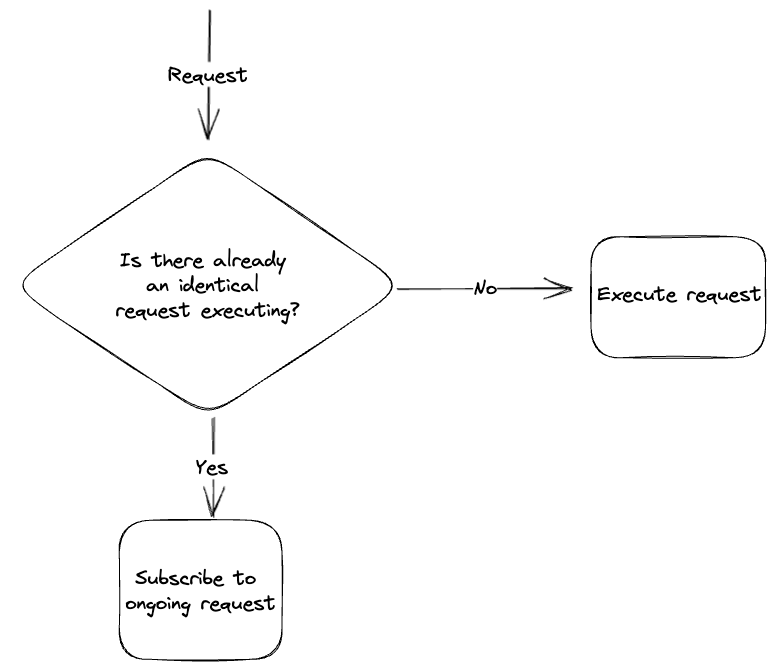
There are few key things to note about this request aggregation:
- Aggregation only applies to database reads, writes should be not be aggregated.
- Only identical requests should be aggregated. You should determine what constitutes an identical request. Eg. a request for all chat messages for a specific channel and time parameters could be seen as identical in a chat-service scenario.
- The data service should not perform any business logic, its sole purpose is aggregating and relaying requests to the database.
There are additional functionalities that a data service could perform such as load-shedding, authorization and caching, but this article will focus only on the aggregation behaviour.
Why use a data service?
A data service can prove to be highly beneficial in scenarios where you have highly concurrent identical requests. In the chat service example, this could be requests for the latest messages from a specific channel when users login to a server. A typical scenario for this is someone doing an @here or @channel , all users receive this notification and simultaneously request the latest messages from that channel.
By doing this request aggregation we get the following benefits:
- Reduced load on the database cluster allowing us to be more efficient with our cluster resources.
- Improved response times for requests that subscribe to an ongoing query. All identical requests that come after the first request will get a response faster than if they initiated the database query.
Why not just use a cache?
A data service might sound similar to a cache but its slightly different. A data service does not store the response of the query which is what a cache would do.
The major benefit of this? No cache invalidation. Deciding how and when to invalidate a cache can be a tricky problem, especially in a distributed environment, and that's the key difference between it and a data service.
How do you handle multiple instances of a data service in production?
In a production environment, you're likely going to run multiple instances of a data service for load-balancing and redundancy purposes. This means requests will not be aggregated as efficiently since identical requests could routed to different instances of your data service.
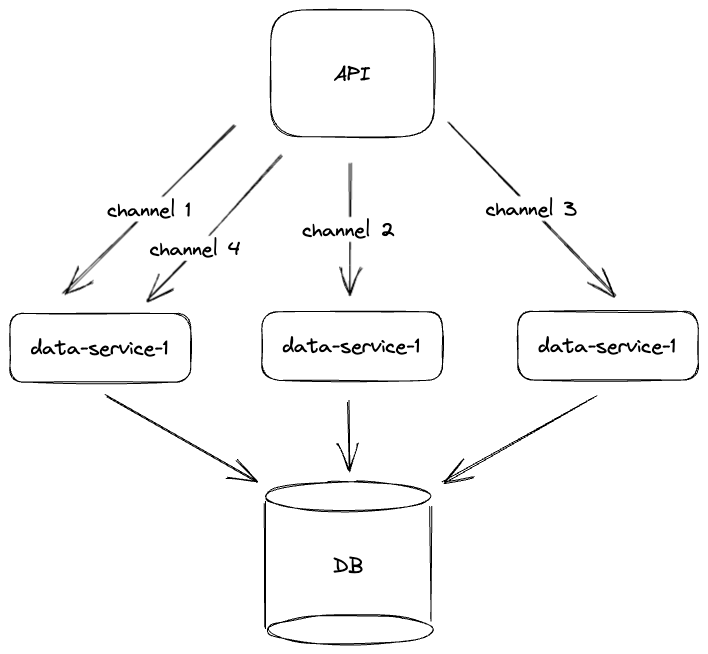
To address this concern, as suggested in the Discord post, we can implement consistent hash-based routing to our data services. In the chat-service scenerio, requests for a specific channel can be routed to a specific instance of our data service.
Analysis of a data service
As with all things in software development, there are pros and cons to every solution.
| Advantages | Disadvantages |
|---|---|
| Improved query performance | Additional network request when fetching data |
| Reduced load on database clusters | Debugging complexity |
| Complexity in handling request failure since multiple requests are tied together |
There might be other considerations to take into account for your specific architecture. Ultimately, you will have to weight these advantages and disadvantages and decide if implementing a data service will be beneficial.
Implementing a data service in NestJS
Now that we've discussed what a data service is, how it works and when to use one, lets look at how we can implement one in NestJS.
If you'd like to see the completed code for this, then checkout the repository below.
 javaadpatel
javaadpatelThe NestJS application that we will build will be a data service proof of concept, focusing specifically on the request aggregation functionality and error handling.
The application architecture, consists of two key modules:
- Message module - Handles requests through a
message controllerand defines the database queries throughmessage service - Task aggregation module - Executes the tasks defined and forwarded by the
message serviceand performs request aggregation.
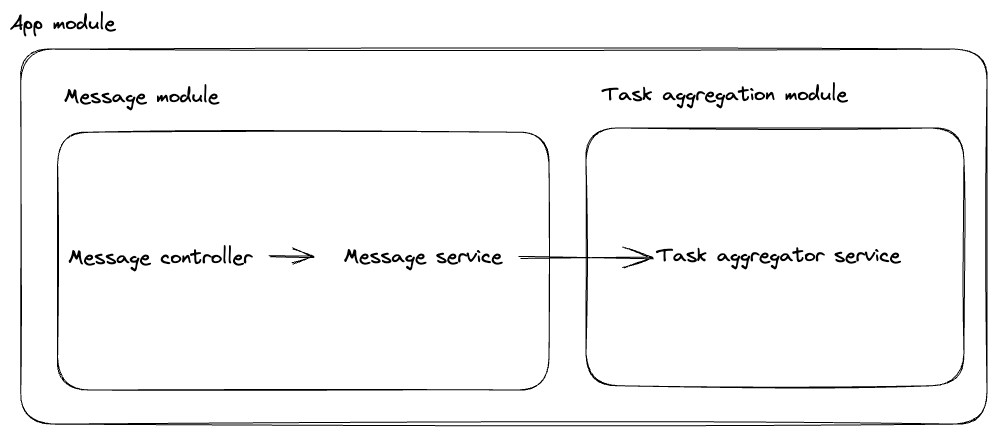
Our MessageService, defines a method getMessages whose responsibility is to define the database query we would like to execute, queue it via the taskAggregator.runTaskObservable and then subscribe to the result of that query.
We use Promise.race to ensure that the request respects a predefined timeout. We use this functionality because the taskAggregator performs retry logic and we want to ensure that the response time is bounded.
@Injectable()
export class MessageService {
private logger = new Logger(MessageService.name)
constructor(
@InjectRepository(Message)
private readonly messageRepo: Repository<Message>,
private readonly taskAggregator: TaskAggregatorService,
) { }
async getMessages(channelId: number): Promise<{}> {
const eventName = `getMessages-${channelId}`;
await this.taskAggregator.runTaskObservable<Message[]>(async () => {
const messages = await this.messageRepo.createQueryBuilder('message')
.where('message.channelId = :channelId', { channelId })
.getMany();
return messages;
}, eventName);
const taskResult$ = this.taskAggregator.getTaskResultObservable(eventName);
// Wait for the task to complete and return the result as an API response
return Promise.race([this.createTimeout(5000), taskResult$.toPromise().then((result) => {
this.logger.log(`total messages served: ${++this.totalCoalescedMessagesServed}`);
return result;
})]);
}
private createTimeout(timeoutInMilliseconds: number) {
return new Promise((resolve, reject) => {
setTimeout(() => {
reject('Task timeout expired');
}, timeoutInMilliseconds);
});
}
}Our TaskAggregatorService, defines a method runTaskObservable which accepts a task to execute and an eventName which is used to detect duplicate requests. In this method we first check if we have an identical task running, if so, we just return. Otherwise, we create a new Subject and add it to our taskResultMap and then we execute the task inside a retry helper.
The retry helper method, retryTask accepts our task to execute and then attempts to retry it a configurable number of times with some delay between attempts.
@Injectable()
export class TaskAggregatorService {
private logger = new Logger(TaskAggregatorService.name);
private taskResultMap = new Map<string, Subject<{}>>();
private totalTasksExecuted = 0;
private retries = 3;
private retryDelayInMilliseconds = 1000;
async runTaskObservable<T>(task: () => Promise<T>, eventName: string) :
Promise<Observable<{}>>{
if (this.getTaskResult(eventName) !== undefined){
return;
}
// If no task is running, create a new observable to emit the task result
const taskResult$ = new Subject<T>();
this.taskResultMap.set(eventName, taskResult$);
this.logger.log(`created subject with eventName: ${eventName}`)
// Your task code here
this.retryTask(task(), this.retries, this.retryDelayInMilliseconds)
.then((result: T) => {
taskResult$.next(result);
taskResult$.complete();
this.logger.log(`total tasks executed: ${++this.totalTasksExecuted}`);
})
.catch((err) => {
taskResult$.error(err);
})
.finally(() => {
this.logger.log(`removing subject with eventName: ${eventName}`)
this.taskResultMap.delete(eventName);
});
}
private retryTask<T>(task: Promise<T>, retries: number, delayInMilliseconds: number) {
return new Promise((resolve, reject) => {
task
.then(resolve)
.catch((error) => {
if (retries === 0){
reject(error);
} else {
setTimeout(() => {
this.retryTask(task, retries - 1, delayInMilliseconds)
.then(resolve)
.catch(reject)
}, delayInMilliseconds);
}
})
})
}
getTaskResultObservable(eventName: string) : Observable<{}>{
return this.taskResultMap.get(eventName).asObservable();
}
}In terms of error handling behaviour, I decided to implement query retry functionality but put a limit on the total request execution time. This covers the scenario where the first request starts executing a query, this query fails and is then retried but during this time a new request subscribes to the query. If in this time the first request times out, the subsequent request will still receive a result.
The full request flow can be visualized as shown below:
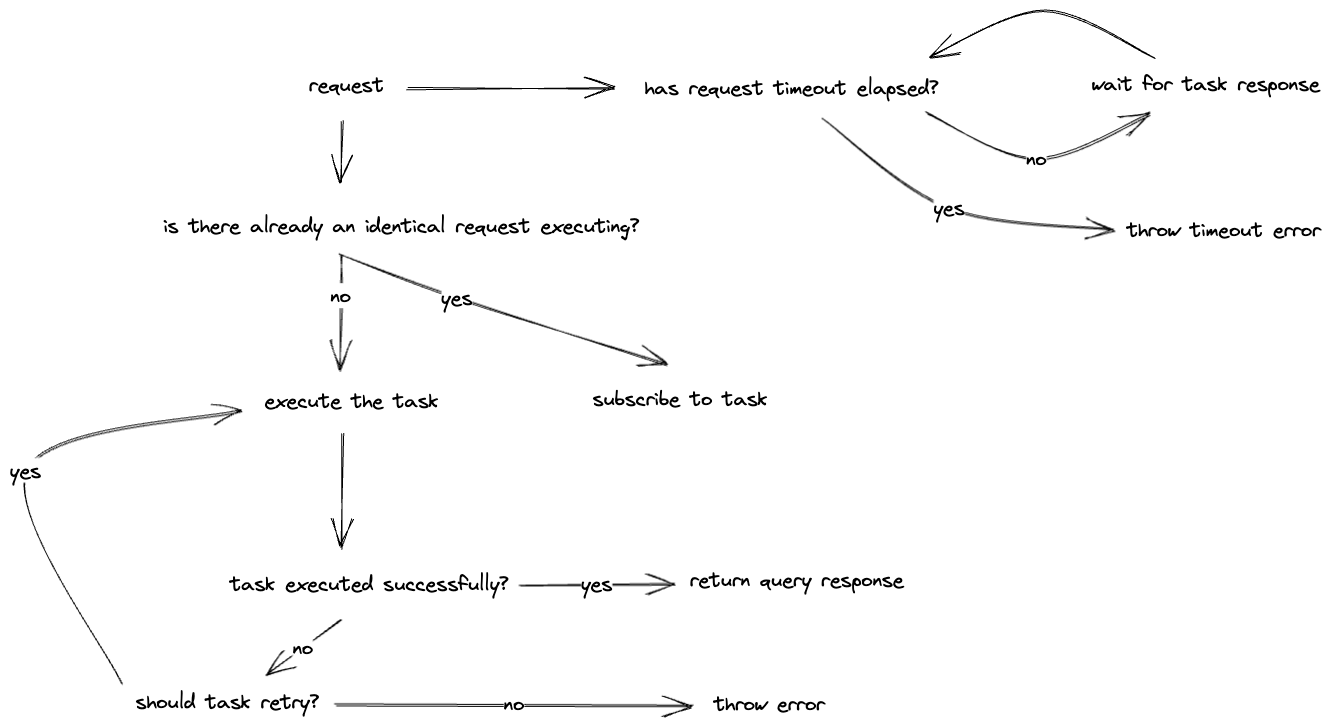
Future thoughts
The idea of a data service is really interesting for improving data fetching request latency and lowering database load. I think that the additional architectural complexity added is offset by the performance gained through aggregation.
There are still some questions that I have not fully explored yet such as; will writes to the database flow through the data service since aggregation is only performed on queries? is there a maximum amount of requests that you would want to aggregate? When I've had an opportunity to test this concept in production, I will write another post to share my learnings on it.
If you have any thoughts or questions, please send me a tweet @javaad_patel