Beginners guide to building high availability systems in Azure - Part 1: Availability Concepts
What does availability mean? In this post we'll learn core availability concepts and architectures to achieve high availability.

This post is part of a series, check out the other posts:
* Part two: Using Terraform for high availability
What is availability and what makes a system highly available? How do you design and build highly available systems? Those are the questions that we'll answer in this series of blog posts.
In the first part of this series, we'll discuss availability concepts and how this applies to a cloud environment, like Azure. We'll walk through what high availability is, core availability concepts, and different architectures to achieve high availability in Azure.
In the second part of this series, we'll explore a strategy to achieve high availability using Infrastructure as Code (IAC), which can be a cost-efficient method for cloud-based applications. We'll use Terraform as our IAC tool and walk through the setup and deployment of an application in Azure. We'll learn how to install Terraform and how Terraform modules and Terraform variables work, along with Terraform best practices.
By the end of this post, you'll understand what high availability is, factors that affect it, and architectures to achieve it.
Availability concepts
In this section, we'll go over availability concepts, how those apply to Azure and what a simple architecture designed for high availability looks like.
What is high availability?
What does it mean for a system to be highly available? Availability is a measure of the system's uptime. Huh? Okay, more simply, the availability of a system represents the likelihood of getting a response from a system. This differs from performance in that, we're not talking about how fast the response is but whether a response is received or not.
Availability is usually measured in percentage terms, most commonly you'll see service level agreements (SLA's) that state that a system has an availability of 99.9% or 99.99%. If we take a look at the table below, we see that for a service that has an availability of 99.9%, there will be ~9 hours every year that the system will be unavailable.
| Availability % | Downtime per year |
|---|---|
| 90% (one nine) | 36.5 days |
| 99% (two nines) | 3.65 days |
| 99.9% (three nines) | 8.76 hours |
| 99.99% (four nines) | 52.56 minutes |
| 99.999% (five nines) | 5.26 minutes |
There are many factors that affect the availability of a system, but the two main are:
- Software failure - Induced when you add new code and introduce bugs, to deal with this kind of failure it's essential to have a phased rollout strategy (if your software runs in multiple regions or you can release to a subset of users) and a good rollback strategy to get things back into a stable state.
- Hardware failure - The hardware your software is running on fails. This type of failure can be local (an individual rack in the data center, or the whole data center) or regional (multiple data centers in the region go down).

In this post, we'll only be looking at designing systems that handle hardware failure.
Availability concepts in Azure
Modern applications are deployed to the cloud and therefore we need to understand the core availability concepts in the cloud. This helps us identify how our application is affected by different types of failures.
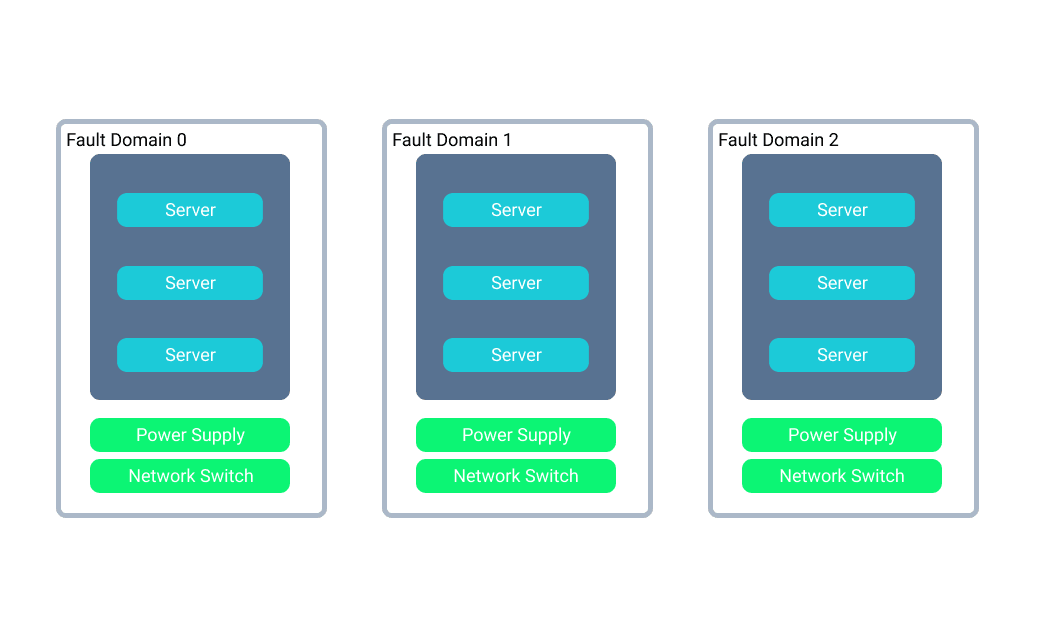
Fault Domains
A fault domain is a rack of servers in a data center that all share the same power supply and network switch. If individual servers fail in a particular domain they can easily be replaced by other servers in the fault domain. But if the power supply or network switch fails it will take down all the servers in that fault domain.
In Azure things like virtual machines can be deployed to particular fault domains or for high availability you can create a virtual machine scale set that would provision servers across multiple fault domains. This ensures that if any individual fault domain goes down your application would still be running on the other domains. A similar concept can be applied with availability sets, which would distribute your application across multiple fault domains.
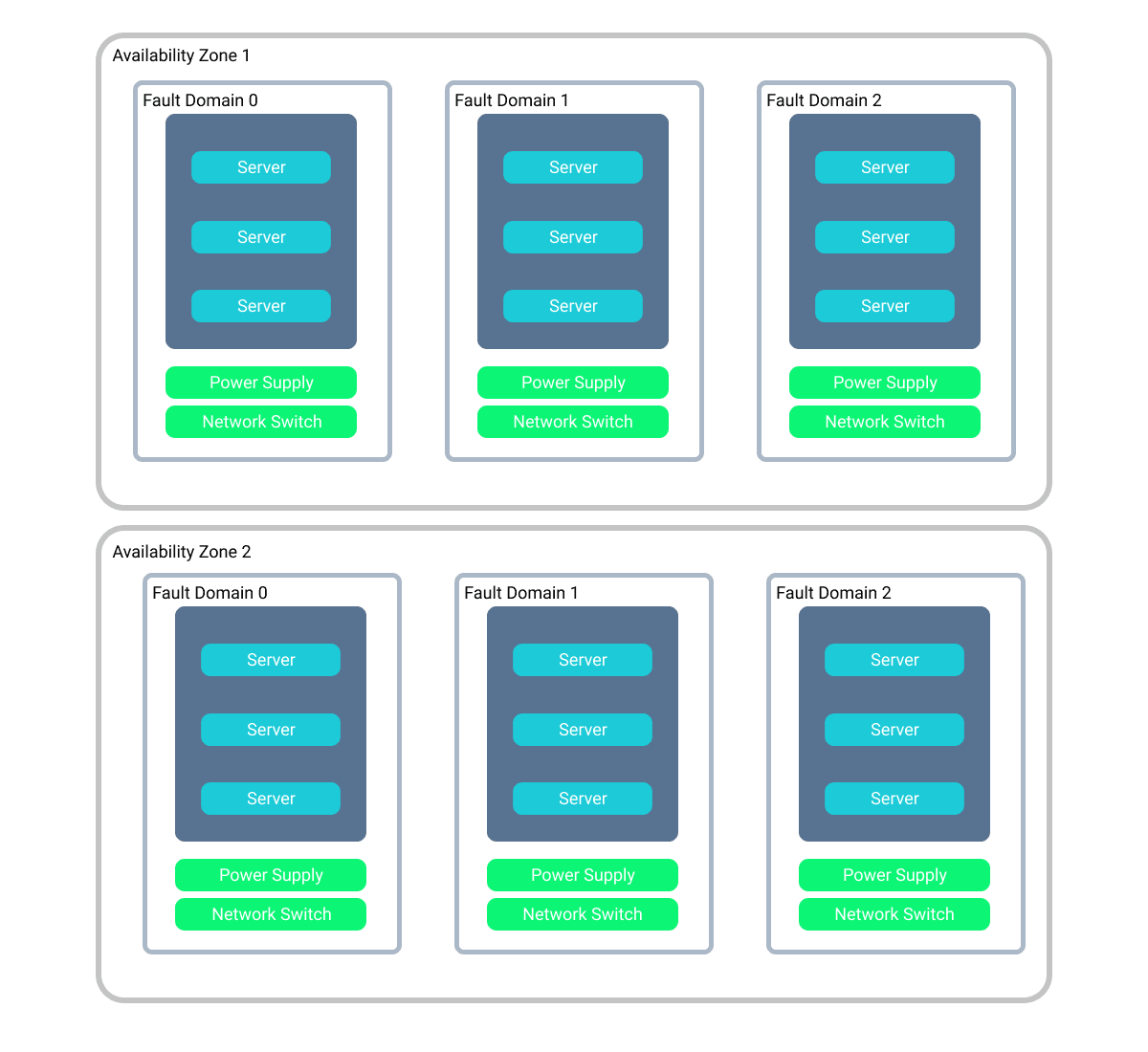
Availability Zones
One level higher we get the concept of availability zones. An availability zone is a data center that consists of these fault domains. These zones all coexist within a particular region (eg. Azure West Europe).
An example of this using multiple availability zones would be something like Azure Storage when using the Zone Redundant Storage (ZRS) option. In this case, your data would be copies three times within one availability zone and then synchronously replicated to another availability zone.
Having your data and application running in multiple availability zones makes the probability of your application being unavailable much lower as your application is now running in two separate physical locations.
There is no distance guarantee in Azure for an availability zone ie. two availability zones might be within sight of one another, but each would have its own separate power and network infrastructure.
Regions
The final availability concept is the concept of a region. A region is a logical grouping of availability zones. Regions in Azure are paired geographically eg. Azure West Europe would be paired with Azure North Europe. This pairing is used for update rollouts, data sovereignty concerns, and priority recovery. So for example, if Azure is rolling out an update it would only roll it out to one of the regions in a pair until everything proved to be stable and only then update the other region.
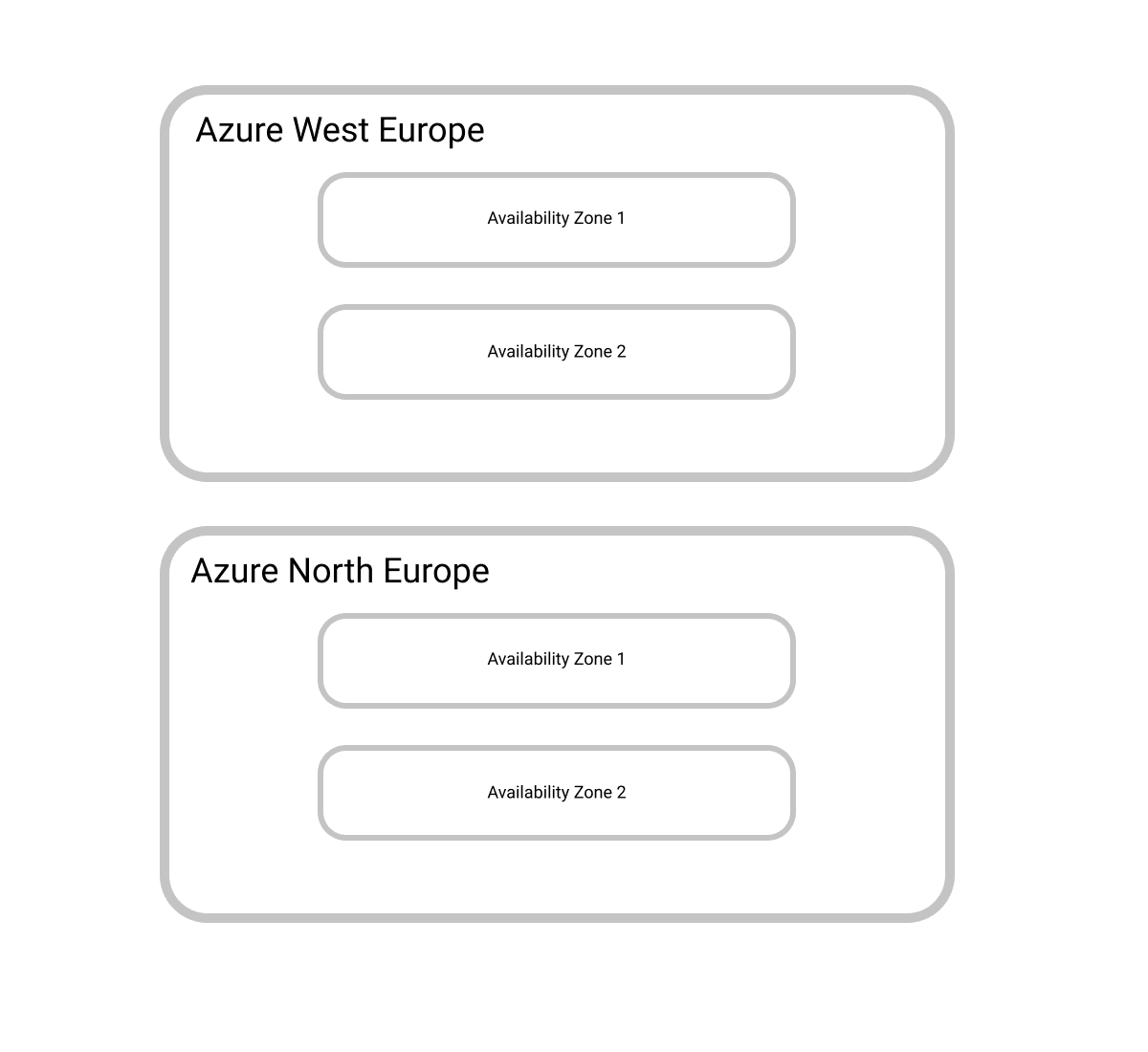
When we consider true high availability architectures, they are usually deployed to at least two regions, isolating them from failure from any particular region. If both regions go out simultaneously you probably having a bigger problem than worrying about your application.

Key disaster recovery metrics
Before we dive into the high availability architectures, there are two key metrics to consider when thinking about availability and those are - Recovery point objective and Recovery time objective.
Recovery Point Objective (RPO)
This is defined as the maximum tolerable amount of data loss. The amount of data loss your system can tolerate without severe business continuity consequences will affect your backup schedule or influence whether you need continuous data replication. If for example, you cannot have any data loss at all for the particular system, then not only would you want continuous data replication but you might want to force that data replication to be synchronous. This would have a performance impact as usually data replication between different regions would be asynchronous, but might be the only way you can guarantee that you won't lose any data.
The RPO your organization defines will differ between business units as the data each unit keeps is of varying importance eg. financial records are harder to recreate and the impact of losing them is much higher. Shown below are some sample timeframes for different business unit types - these are only guidelines.

Recovery Time Objective (RTO)
A recovery time objective is the maximum amount of time that a system can take to restore its operations to an acceptable level. This is dependent on the type of business you're operating, and having a near-zero RTO can be costly. Usually requiring a multi-region architecture, which we'll discuss in the next section.
High availability architecture
As we've discussed, to ensure high availability in the face of regional failure we would want to a multi-region architecture. This is generally done in the following ways:
- Active/passive with hot standby. Traffic goes to one region, while the other waits on hot standby. Hot standby means the VMs in the secondary region are allocated and running at all times.
- Active/passive with cold standby. Traffic goes to one region, while the other waits on cold standby. Cold standby means the VMs in the secondary region are not allocated until needed for failover. This approach costs less to run, but will generally take longer to come online during a failure.
- Active/active. Both regions are active, and requests are load-balanced between them. If one region becomes unavailable, it is taken out of rotation.
Active/active strategies would give the highest availability and also the lowest latencies for global-scale applications, but they do come with the highest expense and complications around data consistency as data is replicated asynchronously between regions.
Most applications would be fine with an active/passive setup and depending on the RPO & RTO you could either go with a hot or cold standby.
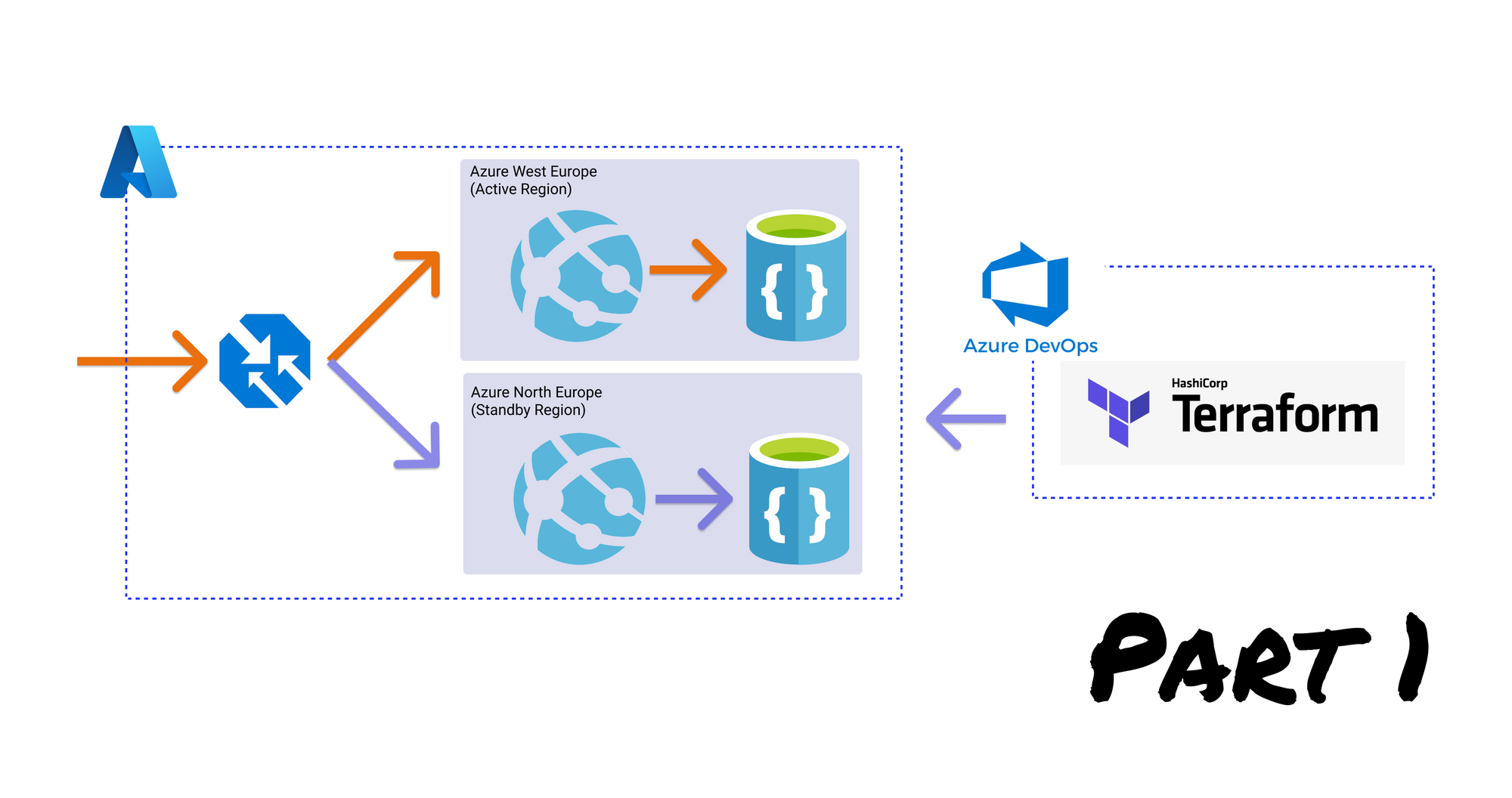
In this series we'll cover an active/passive setup with a cold standby, assuming an RPO and RTO of under 1 hour. The multi-region architecture we'll be exploring is shown below.
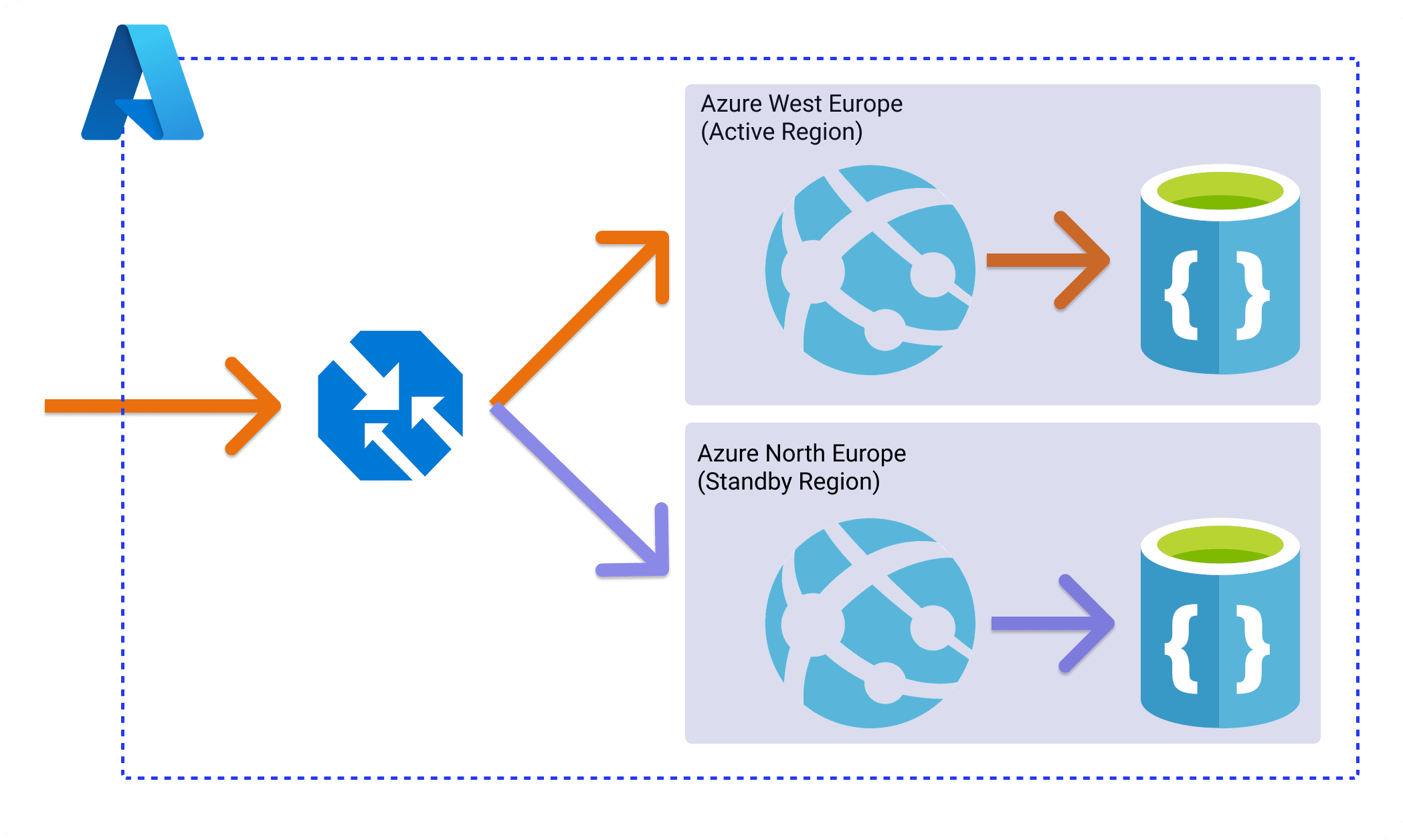
This is an architecture for a web application and I've intentionally kept it simple so we focus on the availability concepts and not specific functionality. In this architecture we have three main components:
- The web application - A template C# web application. The actual application or its language doesn't matter to this demo. We'll be using Azure Web Apps as our Azure PaaS service. The application is deployed into both our primary region Azure West Europe and standby region Azure North Europe.
- The database - An Azure Cosmos DB database with configured replication between the primary region and the standby region.
- The load balancer - We'll use the load balancer as our entry point and have it decide where to send traffic to depending on the availability of a particular region. All traffic will be routed to the primary region and if the primary region goes down we'll redirect that traffic to a secondary region. We'll use Azure Traffic Manager a DNS-based traffic load balancer.
With this architecture, we can achieve a high availability setup by having our application deployed to two different regions and replicating data asynchronously between those regions.
Wrapping up: Azure availability concepts
To summarize, we first defined what is meant by availability and why it's important. We then went through the basic concepts of availability in Azure, from the idea of fault domains being the most atomic unit, to Azure regions at the highest level. We then discussed different architecture setups for achieving high availability like Active/Passive with cold standby.
In the next post, we'll get our hands dirty and implement this multi-region architecture using Terraform and get a practical sense of how we can apply these availability concepts.
